Methodology overview
The goal of this document is to summarise from a conceptual point of view the main points which are different in comparison to the latest NNPDF (i.e. NNPDF3.1) methodology.
Warning
The default implementation of the concepts presented here are implemented with Keras.
The n3fit code inherits its features, so in this document we avoid the discussion of
specific details which can be found in the Keras documentation.
Note
The final setup used in n3fit fits can be extracted from the runcards stored in nnpdf/n3fit/runcards.
This document contains a more specific discussion about the choices currently implemented in the
n3fit package and discussed for the first time in hep-ph/1907.05075.
Table of contents:
Introduction
The approach presented here inherits the technology developed by the NNPDF collaboration in terms of fit pipeline but extends the possibility to test and improve fitting performance with modern techniques inspired by the deep learning community.
The n3fit code is designed in python and replaces the nnfit program used in the NNPDF3.X family of fits.
It provides a simple abstraction layer which simplifies the life of developers when
considering the possibility of adding new fitting algorithms.
In the following table we list some of the differences between both codes:
Component |
|
|
|---|---|---|
Random numbers |
main seed, closure filter seed |
multi seed |
Data management |
libnnpdf |
same as nnfit |
Neural net |
fixed architecture, per flavour |
single net, flexible architecture |
Preprocessing |
random fixed |
fitted in range |
Integration |
a posteriori per iteration |
built into in the model |
Optimizer |
genetic optimizer |
gradient descent |
Stopping |
lookback |
patience |
Positivity |
penalty and threshold |
dynamic penalty, PDF must fulfill positivity |
Postfit |
4-sigma chi2 and arclength |
same as nnfit |
Fine tuning |
manual |
semi-automatic |
Model selection |
closure test |
closure test, hyper optimization |
Input scaling |
(x,log(x)) |
feature scaling |
In nnfit there is a single seed variable stored in the fit runcard which is used to
initialize an instance of the RandomGenerator class which provides random numbers sequentially.
The nnfit user has no independent control over the random number sequences used for the neural
network initialization, the training-validation split and the MC replica generation. On the other
hand, in n3fit we introduce three new seed variables in the fit runcard: trvlseed for the
random numbers used in training-validation, nnseed for the neural network initialization and
mcseed which controls the MC replica generation.
Note
In the next sections we focus on the n3fit specifics marked in bold.
Neural network architecture
The main advantage of using a modern deep learning backend such as Keras consists in the possibility to change the neural network architecture quickly as the developer is not forced to fine tune the code in order to achieve efficient memory management and PDF convolution performance.
The current n3fit code supports feed-forward multilayer perceptron neural networks (also known
as sequential dense networks in ML code frameworks) with custom number of layers, nodes, activation
functions and initializers from Keras.
A big difference in comparison to nnfit is the number of neural networks involved in the fit.
Here we use a single neural network model which maps the input (x, log x) to 8 outputs,
nominally they correspond exactly the 8 PDF flavours defined in NNPDF3.1. Note however that
n3fit also allows for the use for one network per flavour by modifying the layer_type
parameter.
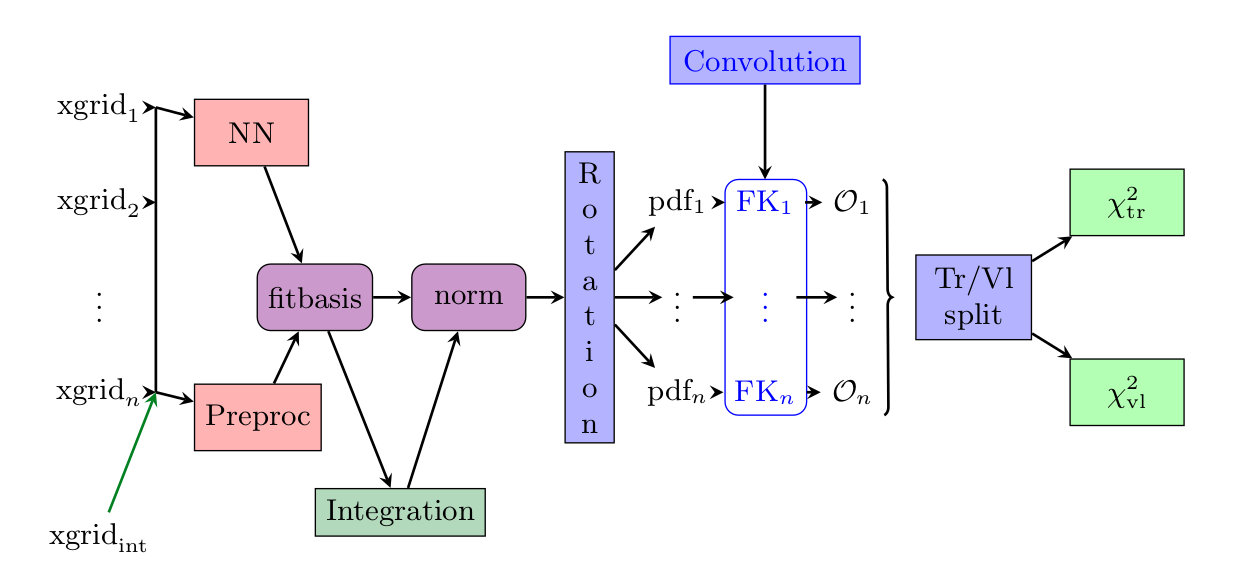
Preprocessing has been modified from fixed random range selection to fitted preprocessing in a bounded range by constraining the exponents to have the norm between a lower bound and an upper bound. The preprocessing ranges are the same used in NNPDF3.1 and thus based on the evolution basis with intrinsic charm.
The momentum sum rules are implemented as a neural network layer which computes the normalization coefficients for each flavour. This layer approximates the integral with a sum over a fixed grid of points in x. This approach guarantees that the model will always be normalized, even if the network parameters are changed, and therefore the gradient descent updates are performed correctly. The number and density of points in x is selected in such way that the final quality of the integrals are at least permille level in comparison to 1D integration algorithms.
The network initialization relies on modern deep learning techniques such as glorot uniform and normal (see Keras initializers), which have demonstrated to provide a faster convergence to the solution.
Important
Parameters like the number of layers, nodes, activation functions are hyper-parameters that require tuning.
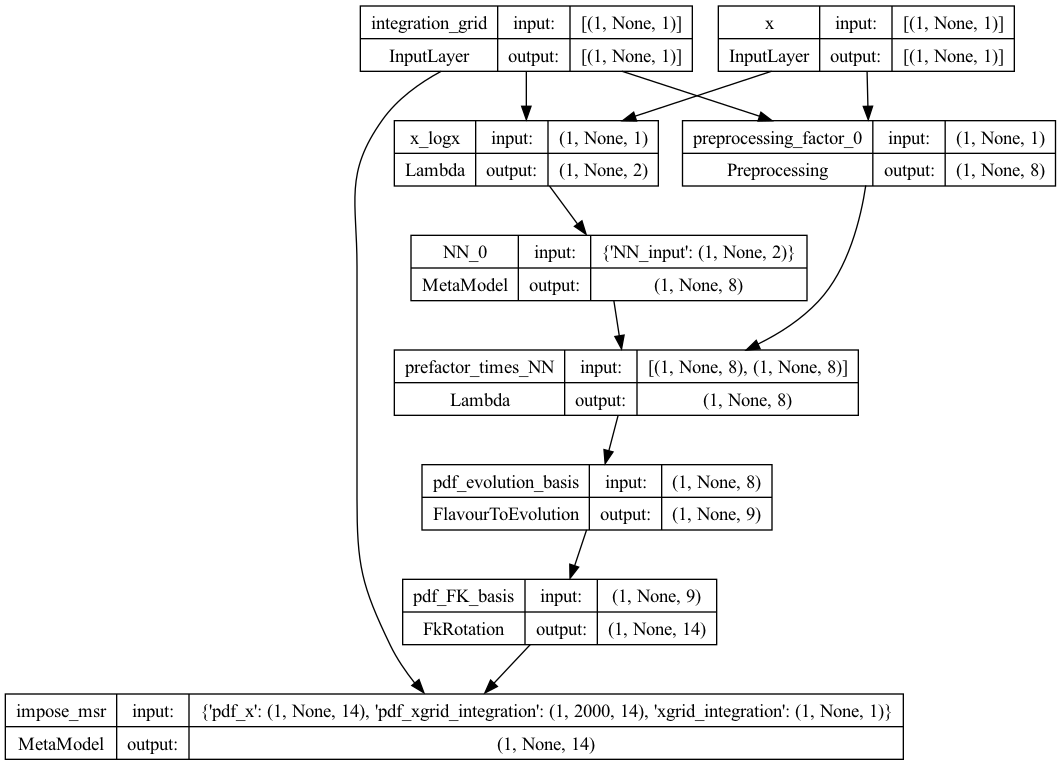
To see the structure of the model, one can use Keras’ plot_model function as illustrated in the script below.
See the this section of the Keras documentation for more details.
from keras.utils import plot_model
from n3fit.model_gen import pdfNN_layer_generator
from validphys.api import API
fit_info = API.fit(fit="NNPDF40_nnlo_as_01180_1000").as_input()
basis_info = fit_info["fitting"]["basis"]
pdf_model = pdfNN_layer_generator(
nodes=[25, 20, 8],
activations=["tanh", "tanh", "linear"],
initializer_name="glorot_normal",
layer_type="dense",
flav_info=basis_info,
fitbasis="EVOL",
out=14,
seed=42,
dropout=0.0,
regularizer=None,
regularizer_args=None,
impose_sumrule="All",
scaler=None,
)
nn_model = pdf_model.get_layer("pdf_input")
msr_model = pdf_model.get_layer("impose_msr")
models_to_plot = {
'plot_pdf': pdf_model,
'plot_nn': nn_model,
'plot_msr': msr_model
}
This will produce for instance the plot of the PDF model below, and can also be used to plot the neural network model, and the momentum sum rule model.
Preprocessing
Preprocessing has been modified from fixed random range selection to fitted preprocessing in a
bounded range. The preprocessing ranges are defined in the the same from NNPDF3.1 and are
defined in the fitting:basis parameter in the nnpdf runcard.
The old behaviour, in which the preprocessing is fixed randomly at the beginning of the fit, can be
recovered by setting the trainable flag to false. See the detailed runcard guide
for more information on how to define the preprocessing.
Optimizer
In n3fit the genetic algorithm optimizer is replaced by modern stochastic gradient descent
algorithms such as RMS propagation, Adam, Adagrad, among others provided by Keras.
The development approach adopted in n3fit includes the abstraction of the optimization
algorithm thus the user has the possibility to extend it with new strategies. By default all
algorithms provided by Keras are available, other algorithms can be used by implementing them in the
appropiate backend.
Following the gradient descent approach the training is performed in iteration steps where:
for each data point the neural network is evaluated (forward propagation)
the accumulated errors of each parameter is computed using the backward propagation algorithm, where starting from the analytical gradient of the loss function as a function of the neural network parameters the errors for each parameter is estimated.
each parameter is updated accordingly to its weight, the gradient direction and the gradient descent update scheme (which controls the convergence step size and speed).
The gradient descent schemes are usually controlled by the learning rate, and the total number of iterations.
Important
The gradient descent scheme (RMSprop, Adagrad, etc.), the learning rate, the number of iteractions are hyper-parameters that require tuning.
Stopping algorithm
n3fit implements a patience algorithm which, together with the positivity
constraints, define when a fit is allowed to stop:
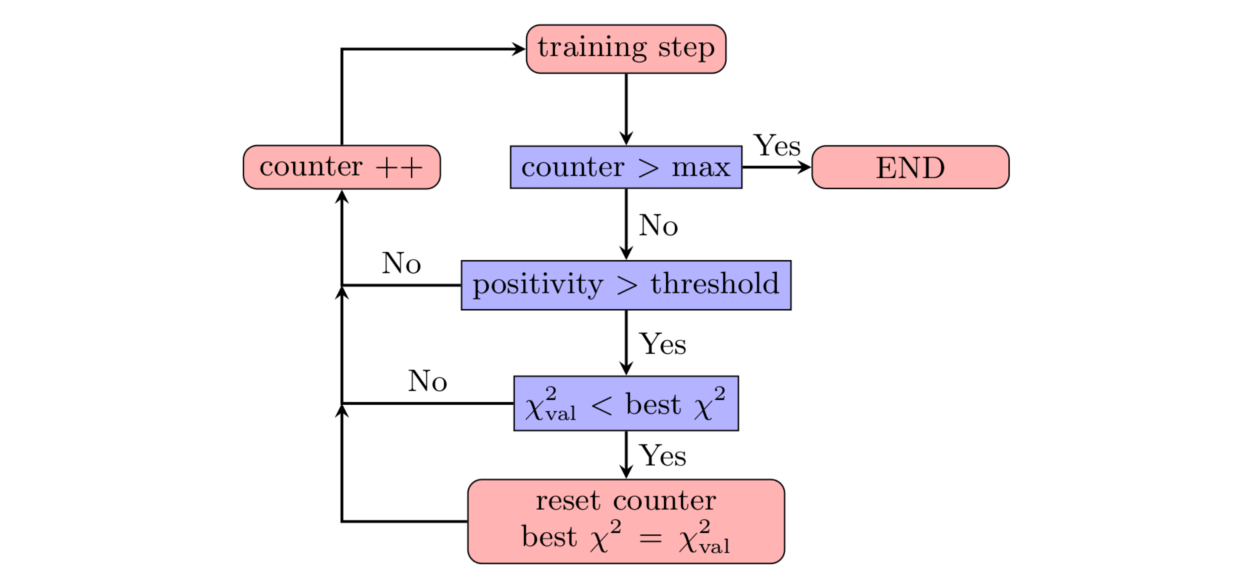
Following the diagram presented in the figure above, we then train the network until the validation stops improving. From that point onwards, and to avoid false positives, we enable a patience algorithm. This algorithm consists on waiting for a number of iterations before actually considering the fit finished. This strategy avoids long fits by terminating the fitting at early stages thanks to the patience tolerance.
If the patience is set to a ratio 1.0 (i.e., wait until all epochs are finished) this algorithm is
equal to that used in nnfit.
The look-back approach implemented in nnfit is not required by n3fit due to its less
stochastic/random path towards the solution.
Important
The patience and the lagrange multipliers are hyper-parameters of the fit which require specific fine tuning.
Positivity
In NNPDF3.1 the positivity of a set of chosen DIS and fixed-target Drell-Yan processes was required:
PDFs were allowed to be negative, as long as these physical cross sections resulted to be positive.
Since \(\overline{MS}\) PDFs have been proved to be positive
it is now convenient to require positivity of the distributions \(q_k = \{u,\bar{u},d,\bar{d},s,\bar{s},g\}\)
themselves. In n3fit this is done on the top of the DIS and Drell-Yan processes already
considered in nnfit.
The implementation of such positivity constraints is based on a penalty term controlled by a positivity multiplier: for each positivity observable \(\mathcal{O}_k\) (which can now be either a PDF or a physical cross section) we add to the total \(\chi^2\) a term of the kind
where \(\Lambda_k\) is the Lagrange multiplier associated with the positivity observable
\(\mathcal{O}_k\). The points \(x_i\) are chosen in the whole \(x\)-region. More
precisely, they consist of 10 points logarithmically spaced between \(5 \times 10^{-7}\) and
\(10^{-1}\) and 10 points linearly spaced between 0.1 and 0.9. The scale at which positivity is
imposed is taken to be \(Q^2 = 5\,GeV^2\). During the minimization, fit solutions giving
negative values of \(\mathcal{O}_k\) will receive a positive contribution to the total
\(\chi^2\) and therefore will be penalized. A similar methodology was already used in nnfit,
to impose positivity of DIS and Drell-Yan physical cross sections.
At the end of the fit, each n3fit replica is tagged with the flags POS_VETO or POS_PASS,
according to whether or not each positivity penalty is greater than a given threshold, set equal to
\(10^{-6}\) (note that the value of this threshold was set differently in nnfit, where less
stringent positivity requirements were implemented). The postfit selection only
accepts replicas which pass all positivity constraints, i.e., only replicas tagged as POS_PASS
are retained.
Note as well that the positivity penalty in n3fit grows dynamically with the fit to facilitate
quick training at early stages of the fit.
Integrability
In order to satisfy valence and Gottfried sum rules, the distributions \(q_k = V,V_3,V_8, T_3, T_8\) have to be integrable at small-\(x\). This implies that
Similarly to what is done for positivity, we can impose this behaviour by adding an additional term to the total \(\chi^2\) which penalizes fit solutions where the integrable distributions do not decrease to zero at small-\(x\). This term is
The specific points \(x_i\) used in this Lagrange multiplier term depend on the basis in which
the fit is performed: when working in the evolution basis, integrability is already imposed through
the choice of preprocessing exponents, and therefore a single small-\(x\) point
\(x=10^{-9}\) is used; when working in the flavour basis, no small-\(x\) preprocessing term
is implemented, and therefore more stringent integrability conditions are used to enforce an
integrable small-\(x\) behaviour. In particular, the three small-\(x\) points
\(x_i = 10^{−5} , 10^{−4} , 10^{−3}\) are used in the definition of the Lagrange multiplier
term above. After the fit, the postfit script will retain just those replicas satisfying a given
numerical definition of integrability, as documented in the postfit
section.
It should be noted that the positivity and integrability multipliers are hyper-parameters of the fit which require specific fine tuning through hyper-optimization.
Feature Scaling
Up to NNPDF4.0 the input to the neural network consisted of an input node (x), which in the
first layer is transformed to (x,log(x)) before being connected to the trainable layers of the
network. The choice for the (x,log(x)) split is motivated by the fact that the pdfs appear to
scale linearly in the large-x region, which is roughly [1e-2,1], while the scaling is
logarithmic in the small-x region below x=1e-2. However, gradient descent based optimizers are
incapable of distinguishing features across many orders of magnitude of x, this choice of input
scaling means that the algorithm is limited to learning features on a logarithmic and linear scale.
To solve this problem there is the possibility to apply a different feature scaling to the input by
adding a feature_scaling_points: [number of points] flag to the n3fit runcard. By adding this
flag the (x,log(x)) scaling is replaced by a scaling in such a way that all input x values
are evenly distributed on the domain [-1,1], and the input node is no longer split in two.
Of course this scaling is discrete while the pdfs must be continuous. Therefore a monotonically
increasing cubic spline is used to interpolate after the scaling has been applied. To this end the
PchipInterpolator
function from the scipy library is used. However, this way the neural network will be agnostic to
the existence of this interpolation function meaning it can no longer learn the true underlying law.
To fix this, the interpolation function has to be probed as well. This is done by only using
[number of points] set by the feature_scaling_points flag to define the interpolation function
after the scaling has been applied. Using this methodology the points used in the interpolation are
again evenly distributed.
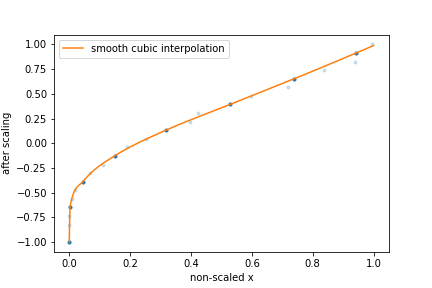
The figure above provides a schematic representation of this feature scaling methodology:
The input
xare mapped onto the[-1,1]domain such that they are evenly distributed.[number of points]points are kept (dark blue), while other points are discarded (light blue).A cubic spline function is used to do the interpolation between the points that have not been discarded.
Diagonal basis
Training and validation data are obtained by performing a random split of the original data set. However, data points in the two sets are not necessarily statistically independent, as they may be correlated through the fitting covariance matrix \(C_{\rm fit}\). Here the fitting covariance matrix is the sum of the \(t_{0}\) experimental covariance matrix \(C_{0}\) and any theory covariance matrix \(C_{\rm th}\) used in the fit, i.e., \(C_{\rm fit} = C_{0} + C_{\rm th}\). In order to disentangle the training and validation data, we perform the training-validation split in a basis in which the correlation matrix is diagonal.
We first compute the correlation matrix \(\rho\), which is defined as
where we have defined \(\Sigma_{ij} = \sqrt{C_{\rm fit, ii}} \delta_{ij}\) and \((\Sigma^{-1})_{ij} = \frac{1}{\sqrt{C_{\rm fit, ii}}} \delta_{ij}\). The correlation matrix is a symmetric positive-definite matrix, and therefore it can be diagonalized by an orthogonal transformation. Therefore we can write
where \(V\) is an orthogonal matrix and \(\Lambda\) is a diagonal matrix containing the eigenvalues of \(\rho\). The original fitting covariance matrix can then be written as
where we have defined the non-orthogonal matrix \(U = \Sigma V\). Its inverse defines the rotation matrix that diagonalizes the \(\chi^2\), and is given by \(R^T \equiv U^{-1} = V^T \Sigma^{-1}\). Therefore, the inverse of the fitting covariance matrix can be written as
Considering the definition of the \(\chi^2\) function in the NNPDF methodology, we finally have
where we have defined the residuals in the diagonal basis as \(\epsilon \equiv R^T(D-T)\) or, writing it in index notation,
In this basis, the \(\chi^2\) becomes a weighted norm of the residuals, where the weights are given by the inverse of the eigenvalues of the correlation matrix.
The transformed data \(\epsilon\) are statistically independent in the diagonal basis of the correlation matrix \(\rho\). As a crosscheck, we can compute the covariance of \(\epsilon\),
where we have used the fact that \(R^T U = I\) and the assumption that the data are distributed according to the fitting covariance matrix \(C_{\rm fit}\)
This shows that the correlation is indeed diagonal, and demonstrates that the training/validation data are uncorrelated.